前言
在PHP7生命周期中会涉及信号的处理在第7.1基础知识中,作者提到了信号处理,并得出结论:
- 可靠信号(>=34)不会丢失,N个可靠信号经过排队,在信号处理的时候仍然是N个。
- 非可靠信号(<34)会丢失,N个非可靠信号经过排队,在信号处理的时候是1个
- sigprocmask系统调用是设置进程的信号掩码(掩码中的信号会进入队列排队处理)的。
- 对于3中进入队列的信号,进程可以通过sigsuspend(&newMask)从队列中取出阻塞信号
在这一小节的学习过程,大家对信号处理都不是很熟悉,理解起来比较费劲,故在这里对该小节中的示例代码进行剖析
知识拓展
在讲解代码之前,先拓展一下信号的相关知识
UNIX信号有1~63个
- 1~31的信号为传统UNIX支持的信号,是不可靠信号(非实时信号)
- 34~63信号是后来扩容的可靠信号(实时信号)
注意:32和33信号是不存在,应该是想区分开这两类信号吧
不可靠信号不支持排队,可能会造成信号丢失
可靠信号支持排队,不会造成信号丢失
可以采用多次发送来进行排队测试
发送信号到进程
1 | kill [-s signal|-p] [--] pid… 向某一进程发送信号 |
需要理解的三个函数
- sigaction():用来查询或设置信号处理方式
- sigprocmask():用于改变进程的当前阻塞信号集,也可以用来检测当前进程的信号掩码
- sigsuspend():在接收到某个信号之前,临时用mask替换进程的信号掩码,并暂停进程执行,直到收到信号为止
实战
我们要验证的就是可靠信号(>=34)不丢失,非可靠信号会丢失这一结论,并理解上述三个函数
我们需要检测到当前进程接收到的信号,并且能根据不同的信号设定不同的响应
首先自定义一个信号处理函数
1 |
|
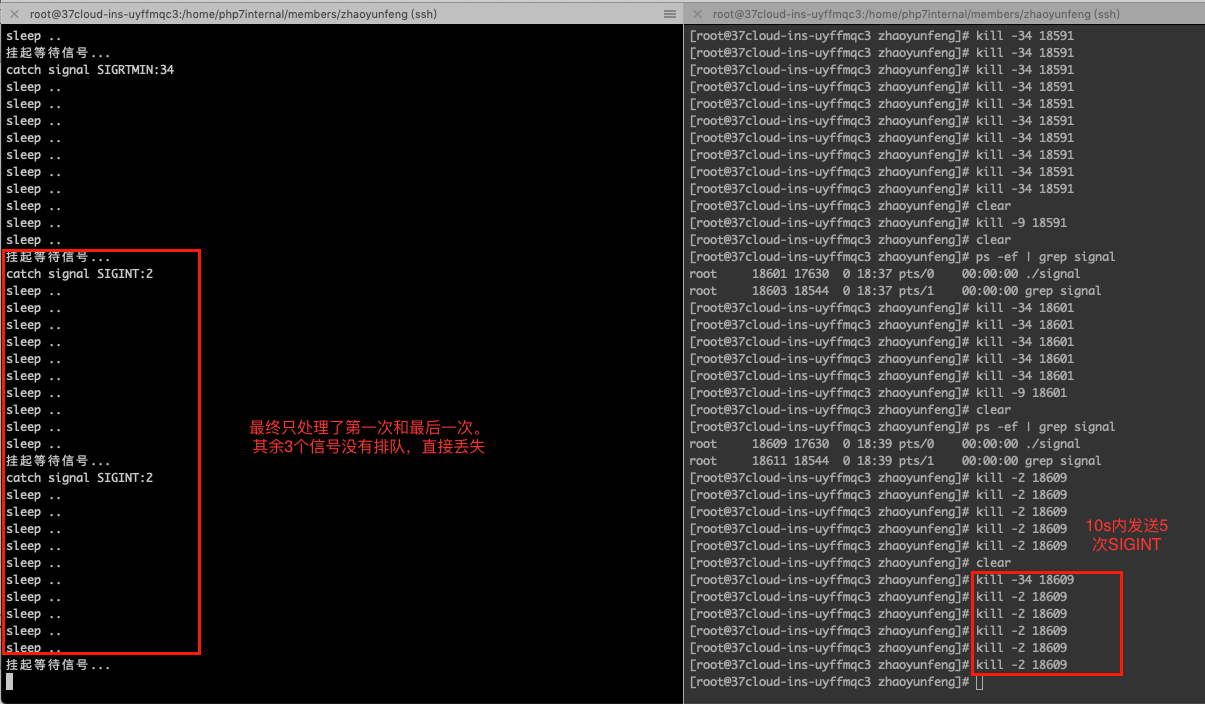
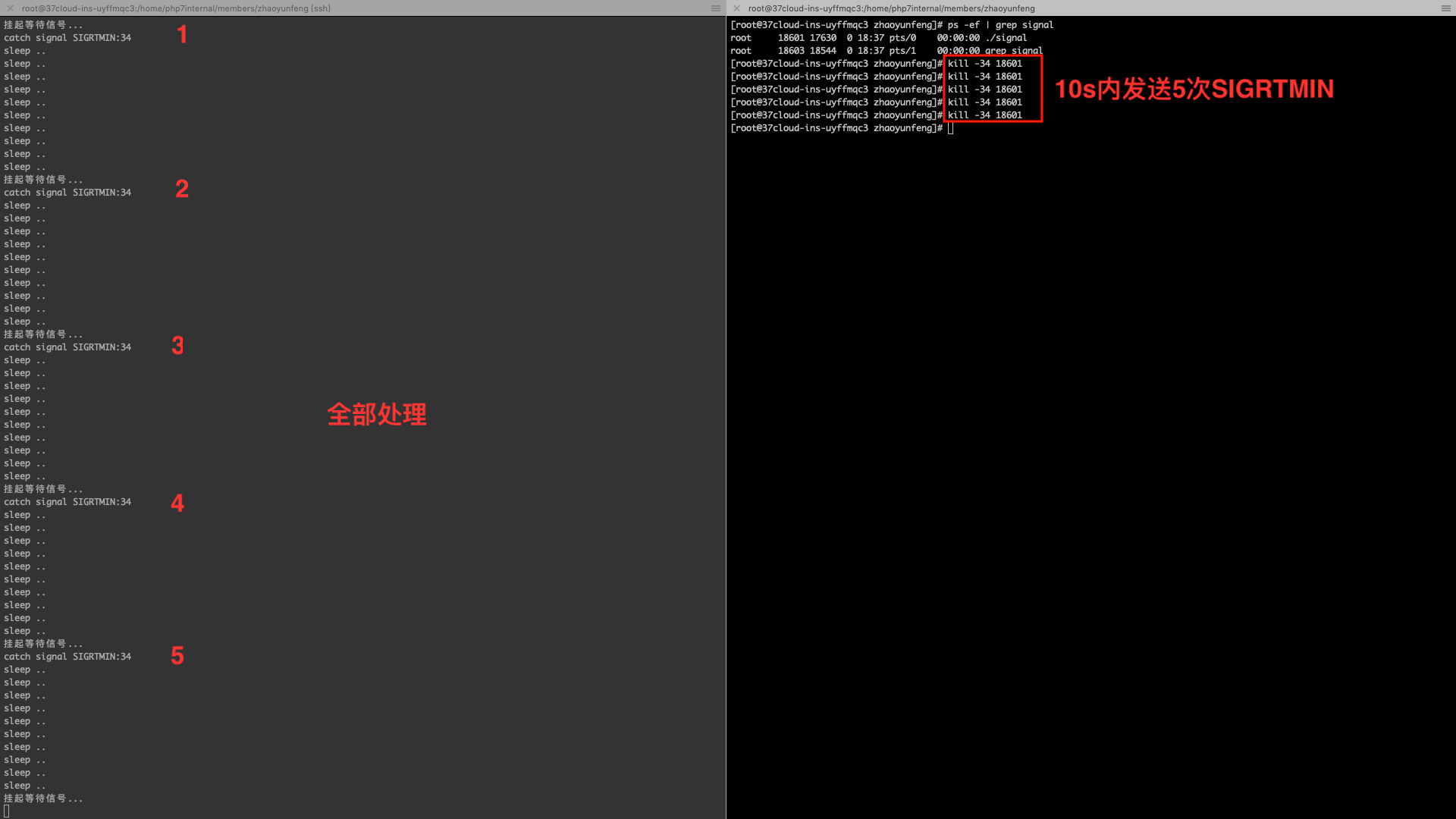
上面程序中每10s才去处理一次信号,可以通过10s内连续发送多个不可靠信号2和10s内连续发送多个可靠信号34
来看程序运行结果1
2gcc signal.c -o signal
./signal
以下是两种信号的执行结果
- 发送可靠信号
- 发送不可靠信号